Geomechanical Data
ResInsight can be built with support for reading and displaying geomechanical analysis models produced by ABAQUS in the *.odb format. This is only possible if you or your organization has a copy of the ODB-Api from Simulia, and a valid license to use it.
If you have, and would like to a use these features, please see Build Instructions for a description on how to build ResInsight and how to include the support for odb-files.
Geo Mechanical Data Support
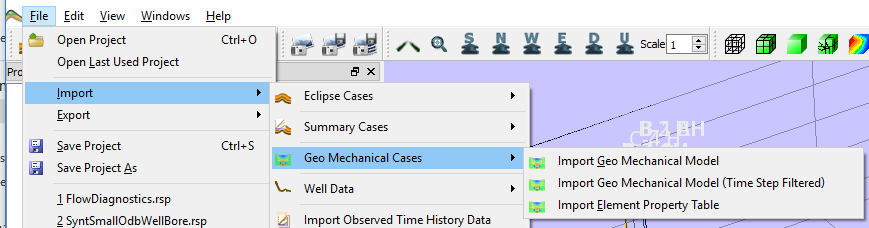
Geo-mechanical data can be imported using the Import -> Geo Mechanical Cases menu. Here three options are present: Import Geo Mechanical Model, Import Geo Mechanical Model (Time Step Filtered) (both for odb files) and Import Element Property Table.
A geomechanical model can also be imported from a VTK file, see Import from VTK Files below.
ResInsight supports the elements C3D8R, C3D8 and C3D8P which are all HEX8 cells. It is also assumed that there are no other element topologies present in the odb file, and that there are only one part. For IJK-based range filters to work, it is also assumed that the elements in the part is topologically arranged as a complete box.
ResInsight loads the second frame within each odb-step, and present those as the time series for each result.
All the result fields in the odb-file is then available for post processing in ResInsight, but stresses and strains are converted to pressure-positive tensors as normally used in geomechanics, instead of the normal tension-positive tensors that ABAQUS stores.
Pressure and stress are always displayed using the Bar unit.
Other derived results are also calculated, and are described in Derived Results
Import from VTK Files
Geomechanical simulation results can also be imported from VTK files. Unlike the *.odb import, this does not require the ODB-Api or a Simulia license, so it is available in a standard build of ResInsight.
To import a VTK model, select Import -> Geo Mechanical Cases -> Import Geo Mechanical Model. In the file dialog, set the file type to VTK file (*.pvd) and select the *.pvd file.
The *.pvd file is a VTK collection file that references one or more *.vtu unstructured-grid files, one per time step. ResInsight reads these as the time series for the model.
The import handles the node and element result fields stored in the files, including tensor data such as stress and strain, and reads nodal displacements for deformation visualization.
The VTK file format is described in detail in VTK Geomechanical Model.
ResInsight Features
Most of the central features of ResInsight visualization setup also applies to ABAQUS Odb models, like range filters and property filters. Well Paths will also show up along with the odb models.
The Octave interface, however, does not support the odb-data yet.
Time Step Filtered Import
By choosing the Import Geo Mechanical Model (Time Step Filtered) option, it is possible to limit the amount of time steps that are imported to improve the speed and reduce the memory use. If this option is chosen a tile step filter dialog is shown after selecting the file to import.
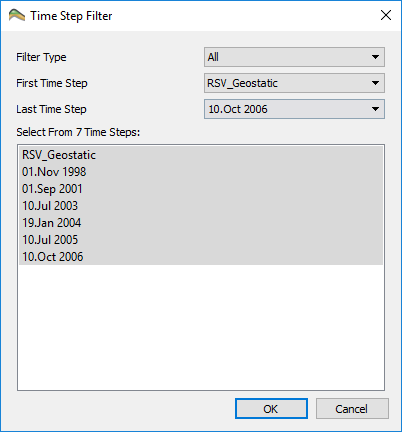
The data can be filtered by skipping Days, Weeks, Months or Years in the top Filter Type drop down list and the range of time steps can be picked in the First Time Step and Last Time Steps lists. Furthermore, the final selection can be fine tuned by selecting or deselecting individual time steps in the Select From N Time Steps list. ResInsight will ignore any data that doesn’t match these time steps and will thus reduce the amount of data imported.